STAT-04: Statistical Techniques for Design Verification
This is part of a series of articles covering the procedures in the book Statistical Procedures for the Medical Device Industry.
Purpose
Design verification studies are confirmatory studies to ensure the product design performs as intended. They make pass/fail decisions as to whether the product’s design outputs (specifications, drawings) ensure each design input requirement (requirements definition document) is met or not. The procedure determines which design requirements require statistical methods to verify them and then helps to select the best method.
Note: It is the goal of Process Validation to show the process is capable of meeting the specifications for the design outputs. It is the goal of design verification to show that the entire specification of the design output result is product that works (meets the design inputs).
Highlights
Sometimes Statistical Methods are not Required – When no variation
- Rules for deciding if testing 1 unit is sufficient. This is for requirements where there is no variation in performing the test. One example is logic testing of software where each test is performed once because the same result will occur each time the test is performed. In software validation, the focus is identifying all the logic paths and testing each one once as part of a test script. This option and approach also applies to other features such as color and presence of a feature.
There are Several Alternatives to Sampling Plans – When there is variation
- Demonstration by Analysis. Examples of Demonstration by Analysis include tolerance analysis, finite element analysis, and models developed by designed experiments. Testing is sometimes, but not always required, to demonstrate the model is predictive. For example, a confirmation run at the optimal settings following a designed experiment. The model is then used to demonstrate that as the design outputs vary over the design space, the product performance meets the design inputs.
- Worst-case testing allowing 1-5 units to be tested at each worst-case setting. Worst-case conditions are the settings for the design outputs that cause the worst-case performance of the design inputs. When worst-case conditions can be identified and units can be precisely built at or modified to these worst-case conditions, a single unit may be tested at each of the worst-case conditions. This ensures the design functions over the entire specification range. This approach is generally preferable to testing a larger number of units toward the middle of the specification range. When units cannot be precisely built at or modified to these worst-case conditions, multiple units may have to be built and tested.
Instructions for Selecting Sampling Plans
- Sampling plans are selected based on the confidence statement that can be made if they pass. For example, 95% confidence more than 99% of the units meet the requirement (denoted 95%/99%). When a sampling plan is required, instructions are provided for linking the confidence statement to risk using a table like the one below.
Hello,
Thanks for this clear sample plan.
I have a question about these sentences “Multiple tests on the same unit. A sample size is 30 means 30 tests are required. Under certain circumstance if may be possible to test 3 units 10 times each.”
Can you detail these circumstances please?
Have a great day.
Best regards,
Thierry.
One example is hardware like a glucose meter where 3 units can be tested 10 times each. It assumes the difference between the meters is small compared to the overall variation in the data. The key is repeated measures on the same unit vary as much as measurements on different units. An example of where it cannot be done is when the 10 measurements on one unit are close together but very different than the 10 measurements on the second and third units.
In order to justify using a small number of units with multiple runs to achieve the desired samples size, would I first have to show that the variance between the units is negligible using an F-test? I am proposing the following to save on unit cost for verification testing
Based on risk, I want to show 95%/95% confidence and reliability. I need at least n=59 a=0 for my sampling plan to achieve this. I don’t want to test 59 individual units because the units are costly. If I run 3 units with 10 runs each and do F-tests to show that the units have equal variance then is that enough justification to allow me to pool the 60 samples among the 3 units for reliability and confidence acceptance criteria?
Thank you for your expertise and input.
What would be best way of justifying this assumption using n=3 units with 10 runs each?, “It assumes the difference between the meters is small compared to the overall variation in the data.”
Would you do an F-test on the 3 units to show that there is equal variability among the units to then justify pooling the multiple runs (n=10) on each unit?
By performing a variance components analysis and demonstrating the between-lot standard deviation is less than 30% of the total standard deviation. Variance components analysis is covered in Appendix C of STAT-08. An example is given in STAT-03, Appendix C.
Where did 15 come from in the following paragraph:
“Variables data – having a measurement instead of attribute pass/fail results, allows variable sampling plans to be used. They require as few as 15 samples in contrast to the minimum of 299 above.”
My tables of variables sampling plans range from 15-100 samples. The 15 is due to the assumption of normality. Less than 15 samples does not provide enough data for verifying the normality assumption. While 15 is minimum, I would generally recommend 50 samples for mormaility test. 15 is less than I would like but still tolerable. It is sufficient to detect larger departures from normality which have the largest effect on the variable sampling plan.
I’m new to testing for normality… am I understanding this correctly:
– Quantity 50 is suggested minimum per best practice but it might go as low as 15; but neither of these numbers are a hard rule or are published in a whitepaper/journal etc?
– I’m seeing people on forums claiming normality with a sample size of 3 using the Sharipo-Wilk test… which makes no sense to me because normality tests don’t actually confirm normality. All these people really did was prove that the data was no too grossly non-normal to fail the test?
50 is my suggested number for testing for normality relative to acceptance sampling. Too large of number can lead to rejecting the normal distribution for small departures which have little effect on the sampling plan. I suggest 15-100, ideally 50.
You are correct that normality tests do not prove normality. Instead, they detect sizeable departures from normality. The size of the departure detected depends on the sample size. Less than 15 is too few samples. More than 100 is too many samples. With 3 samples, the normality test will almost always pass even for very nonnormal data.
What is your say about lot to lot variation requirment for design verification? As you said intent of design verification is about meeting design output with design input, so I don\\\’t think getting calculated sample size from different lots is required for design verification
Different lots are not required but a representative sample of the design space is. The samples should cover the majority of the design space or some other strategy like worst-case testing or demonstration by analysis should be used. All are explained in STAT-04. If samples cover a small portion of the design outputs, while the resulting units may perform acceptably, production may use a larger portion of the design space and not function as well.
Is the product risk/harm level mentioned in your design verification sampling table pre-mitigated or post-mitigated? If this is post-mitigated, Isn’t design verification the mitigation of the risk. So how can we test for a post-mitigated risk level when we have not completed design verification yet?
In my book for Design Verification, I mention that the confidence statement should be set based on Risk/Harm. On pages 2-3, I suggest basing the confidence statement on Severity and possible P2 as the best approach. The confidence statement proves the Occurrence (O) or P1 components of risk are at an acceptable level for the associated Severity and P2. This means the confidence statement is based on neither the pre-mitigated or post-mitigated risk, just Severity and P2.
I recognize some companies use RPN instead. In this case, I recommend that Severities 4 and 5 be assigned to the highest level regardless of RPN. RPN is then only for lower severity items.
Thanks for all theses precious information. I’d like to make sure I understand how to use stress tests to reduce the number of samples. If I have to demonstrate 95/95 with a test by attribute, does a margin of 10 on the test conditions allow me to use 5 samples instead of 59 initially. Thank for your expertise.
If the stress test causes 10 times as many units to fail as during normal usage, then 5 samples can be tested under the stress conditions rather than 59 under normal usage conditions. 5% failures under normal usage correspond to 50% failures under stress conditions.
Please show me the proof for the following in your design verification blog:
Design Verification Reduced Level (Stress Tests)
High 95% / 99% 95% / 95%
Moderate 95% / 97% 95% / 90%
Low 95% / 90% 95% / 80%
OR
– If the stress test causes 10 times as many units to fail as during normal usage, then 5 samples can be tested under the stress conditions rather than 59 under normal usage conditions. 5% failures under normal usage correspond to 50% failures under stress conditions.
The stress levels given in the table in my book are easy to achieve levels, so granted upon establishing the test is a stress test without having to prove the level of the stress test. If you can prove it is a 10 times stress test, meaning ten times the number of units will fail under test conditions compared to usage conditions, then you can reduce the sample size by a factor of 10.
Dr. Taylor can you please clarify again when “Multiple tests on the same unit” is and is not acceptable? I see common practice of testing the same units multiple times, such as 3 units/10 times to achieve “N=30” in order to show that the design will consistently meet spec but I would consider that as actually N=3 as units multiple times is not the same as a sample of the population. Can you clarify?
Page 65 of my book of procedures describes how the variation between the units must be small compared to the variation within the units.
7.4.4 Performing Multiple Tests on the Same Unit of Product
In some cases, the performance might not vary between units of product, but the characteristic might vary due to usage conditions and patient type. In this case, one to three devices might be tested multiple times each. The sample size of the sampling plan
is then the number of tests performed and not the number of units of product that must be tested. These tests should be split equally between the different units of product. For example, for patient migration when raising and lowering a bed, three beds might be tested using a variety of patients. Showing the differences between beds is very small could even result in a justification for testing a single bed using a variety of patients. To use this approach, evidence of small between-unit variation must be provided, as explained in Appendix C of STAT-03. Instruments correspond to lots in Appendix C (page 51).
Page 51 establishes multiple tests on the same unit assumes the between-unit standard deviation is less than 30% of the total standard deviation. This ensures the between-unit variation increases the total standard deviation by less than 5% and is thus an insignificant source of variation. It describes how to perform a variance components analysis to verify this assumption is met.
Hi Dr Taylor,
Could you explain how you can limit worst case scenario testing down to 1-5 units.
Thanks
You can ensure the specification range is covered with a single unit at each worst-case condition if you can build units precisely at the worst-case limits.
Section 7.3.2 states “When units cannot be precisely built at or modified to these worst-case conditions, multiple units may have to be built and tested. No more than five tests are required, as this provides 95% confidence at least one test is more extreme that the targeted worst-case conditions.” The assumption is that will you cannot precisely build units at the worst-case conditions, you can target the worst-case conditions so that each unit has a 50/50 chance of being inside the specification limit. The chance that all 5 units are inside the specification limit is 0.5^5 = 0.03125. The probability of having at least one unit at or outside the specification limit is then 0.96875, giving 96.875% confidence the five units cover the specification range. If you cannot target at worst-case conditions, worst-case testing is not an option.
In your book, in STAT-04 7.3.2 worst case you give an example where worst case samples cannot be made that no more than 5 samples need to be tested. Can you please explain how you arrive at no more than 5 samples.
Section 7.3.2 states “When units cannot be precisely built at or modified to these worst-case conditions, multiple units may have to be built and tested. No more than five tests are required, as this provides 95% confidence at least one test is more extreme that the targeted worst-case conditions.” The assumption is that will you cannot precisely build units at the worst-case conditions, you can target the worst-case conditions so that each unit has a 50/50 chance of being inside the specification limit. The chance that all 5 units are inside the specification limit is 0.5^5 = 0.03125. The probability of having at least one unit at or outside the specification limit is then 0.96875, giving 96.875% confidence the five units cover the specification range. If you cannot target at worst-case conditions, worst-case testing is not an option.
Got it now. Thank you
Can you please explain in a bit more detail how testing for multiple characteristics for attribute testing allows you to use 90% confidence limits. Many thanks
Suppose there are six characteristics of the same severity. 95%/99% protection is desired. There are three variables and three attributes. A 95%/99% variables plan is used for each of the three variables. Each is demonstrated to be below 1% non-conforming. In total, they are below 3%. The 95%/99% attribute plan n=299, a=0, is used for the three attributes. Passing this plan allows you to not only say each attribute is below 1% nonconforming, but it also allows you to say the three attributes combined are below 1%. This is because attributes are inspected as a group while variables are inspected individually. The end result is that in total, the percent nonconforming is below 4%, 3% for variables and 1% for attributes. Despite the effort to treat everything equally, there is better protection the attribute. One way of making things more equal is to relax the confidence level to 90% for attributes.
Thank you once again
I have one more question if you don’t mind.
If I use a stress test to reduce the sample plan, do I need calculate how many more failures the test is generating compared to the standard test. For instance, if I need to test to prove an endoscope can overcome a certain amount of resistance and not kink or bend, I believe I could create a stress test by increasing the resistance I use in the test by 10 or 20% above the pass criteria. If I did this, could I then use the stress test percent performing sample plan or do I also have to demonstrate how many more failures the stress test generates.
A stress test is a test performed in a way that caused more units to fail than will fail under actual usage conditions. A 5X stress test causes five times as many units to fail. Tables 4 in Stat-03, Statistical Techniques for Process Validation and Stat-04, Statistical Techniques for Design Verification, reduce the inspection level based on stating the test is a stress test. They provide minimal reductions of 5X and less. For forces, worst-case testing can be demonstrated to be a 5X stress test demonstrating 5X is easily achieved. If you want to claim a higher stress level, you need to prove it using data or analysis.
Thanks Wayne, I have one more question if you don’t mind. If I develop a stress test, do I need to establish how much the failure rate has increased by to then use the reduced stress test sampling plan. For example, if I want to test an endoscope is capable of overcoming a certain insertion resistance. If I test at say 10 or 20% greater resistance then the specification, would this justify the test being a stress test and therefore the use of a reduced stress test sample plan.
I would think 20% could be considered a stress test.
Dr Taylor,
In practice, I am seeing that a lot of medical device companies are considering 30 minimum samples for DV variable testing.
In your book, Page 64, it is mentioned that the N= 30 samples can be used for Design Verification testing while Ppk = 1.03. Can you explain how this 30 sample is calculated and how we ended up with 95%/99% C/R? In the book, it is explained that the sample distribution should be normal for this case.
Also in a training by FDA, (Statistical Techniques, 13 July 2022, Michelle Glembin), they explain that a minimum 30 samples are required for such testing when the distribution of the population is not normal or unknown based on Central Limit Theorem. So in this case we can use 30 samples without even checking the normality?
Passing a variables sampling plan allows a Confidence/Reliability statement to be make. Besides the 95%/99% plan n=30, Ppk=1.03, my book gives the plans n=15, Ppk=1.18 and n=100, Ppk=0.90. Passing any of these sampling plans allow the same 95%/99% statement to be made. What differs between these plans is the chance of a false rejection. The book’s tables provide an AQL column for match against the expected performance to determine the best sample size to use. The better the expected performance, the smaller the sample size. However, regardless of which plan is selected, passing it allows the stated C/R statement to be made. Always picking n=30 is an allowed practice, put not the best practice.
Variables sampling plans assume normality. Normality should be tested for regardless of the sample size.
The central limit theorem states that averages tend to the normal distribution as the sample size increases. Averages based on 30 values tend to be quite normal. This is why techniques that compare and model averages tend to be robust to the assumption of normality including t-tests, ANOVAs and regressions. However, variables sampling plans make statements about the tails of the distribution so the central limit theorem does not apply. The same Ppk value results in different defect levels for different distributions.
For a given n and Ppk, an OC curve can be constructed showing the probability of acceptance as a function of the defect rate. For a given n, the Ppk can be adjusted to get the desired C/R statement so for a given n there are 95%/90%, 95%/99% and 95%/99.99% plans. This is why the tables of variables sampling plans have the same range of sample sizes regardless of the C/R statement. The book’s table give an AQL column to help determine the sample size that is likely to pass basedon the expected performance and allowing the C/R statement to be made.
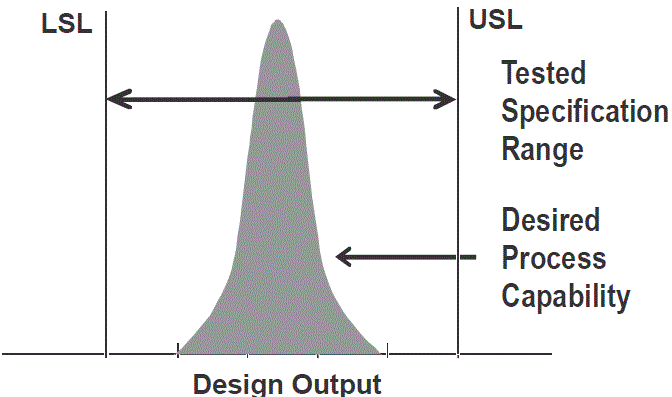
Hello Dr ,
I tried to understand this note “It is the goal of Process Validation to show the process is capable of meeting the specifications for the design outputs. It is the goal of design verification to show that the entire specification of the design output result is product that works (meets the design inputs)” along the with the image provided below to the note. Could you detail the connection/relationship between process capability and design output (under the context of design verification) ?
Thanks
When the product is designed, there may not yet be a process developed. In fact, the tolerances set for design outputs during design may determine the process required to meet those tolerances. However, when processes exist with known capabilities, these can be factored into the product design as any time a tolerance for a design output that is tighter than the process capability it creates a manufacturability issue.
During product design, tolerances are set for the design outputs (design space) to ensure that if they are met, the design input requirements are met. Then during process validation, we show the process meets the design space ensuring the design inputs are met. It creates a risk if during design verification it is shown units produced by the process meet the design inputs but the units produced cover only a small portion of the design space. In the future, the process may then wander into untested portions of the design space and produce bad products.
Dr Taylor,
May i ask a question about the worst case scenario. EX. i have a design space of 0.10 mm-0.20mm and the worst setting is to the lower spec for a product requirement. in this case, how do i prepare the samples? i mean we cannot build samples with exact dimension on 0.10mm, so is there an acceptable range for this? Thanks.
When a single unit cannot be produced at exactly the worst-case conditions, an option is to produce 5 units targeted at the worst-case conditions, where some could be below and some above the worst-case condition. This gives 95% confidence at least one unit is at or beyond the worst-case condition.
On page 59 of my book Statistical Procedures for the Medical Device Industry, there is a reference to this option.
Dr Taylor,
If we get a unit beyond the worst-case condition, why do we still need to perform testing on the other units that are not at /beyond worst-case condition? Shouldn’t it be sufficient to simply test the one that is beyond worst-case condition?
Yes, so long as worst-case includes all the design outputs affecting the design input being tested.
Dr.Taylor,
Is it possible to ruduce the sample size for design validation if I planned to be process validation with a higher reliability or 100% inspection?
100% inspection of a characteristic can be used to justify not doing process validation of the characteristic and for reducing design verification.
To defer design verification testing until process validation you have to meet both sets of requirements during process validation. In design verification the goal is to show over the entire range of the design outputs (called the design space), the design inputs will meet their requirements. In process validation you must show the process produces units inside the design space. It is possible that due to excellent process capability, the process validation units only cover a small portion of the design space rather than the full design space, as required by design verification. Maybe this can be accomplished during OQ. Further you must include all the design inputs in addition to the design outputs.
Hello Dr,
I believe the idea behind providing c>0 single attribute sampling plans in a sampling scheme is an option for tests expected to have failures? And there comes the double sampling plan for the same purpose. How does single sampling plans c>0 and double sampling plans work under the same context? How should one reason with the corresponding AQL value while selecting a single/double attribute sampling plan?
What methods do you follow for solving n while designing single attribute sampling plans with c>0. c=0 plans are pretty straightforward. It is being questioned on how the solutions are arrived for c>0 and the accuracy of the method used. I believe the approach is solving those two simultaneous non-linear equations using any advanced solvers.
Br,
Arun Ariyapattan
All process are expected to have failures at some low rate. They can be characterized by what they accept AQL and what they reject RQL (see Acceptance Sampling Update).
Single sampling plans have two parameters: n = samples size and c = accept number. You can pick any two of AQL, RQL, n and a and then calculate the other two. For c=0 plans if you select the RQL you then calculate n and the AQL. c=0 plans have an AQL that defines failures rates expected to pass the sampling plan. It is just that when you specify c=0 and the RQL, you cannot specify what the AQL is.
For C>1, you can specify the AQL and RQL and then calculate n and c. It does require a program to solve two nonlinear equations restricted to integer solutions for n and c. For double sampling plans there are five parameters rather than two so there is not a unique solution. Criteria for selecting between them can be incorporated including minimizing the Average Sample Number (ASN). My Ph.D. thesis involved writing a program to find the double sampling plan for a specified AQL and RQL minimizing the ASN(p):
“A Program for Selecting Efficient Double Sampling Plans,” Journal of Quality Technology,” Volume 18, Number 1, January 1986, p 67-73.
This program has been implemented in the Sampling Plan Analyzer software package.
Hello Dr. Taylor,
I see in your example that a fivefold increase in the stress level can be used to reduce sample size by 5 (n=300 and a=0 to achieve 95% confidence of 99% reliability becomes n=60 and a=0 with a fivefold increase in stress). Is the same logic applicable if the number of failures is nonzero? For example, with a stress test producing three times as many failures, does n=95, a=1 (95% confidence and 95% reliability) become n=32, a=1?
Yes, when the accept numbers are less than 50% of the two sample sizes.
Hi Dr. Taylor,
For medical device testing, if the team is following the stress testing approach for attribute testing, in the table with the risk level, design verification and stress test, should that be interpreted as (1) “since stress testing is used, a reduced reliability of 95/95 is acceptable since a higher failure rate is anticipated with stress testing” or (2) “since stress testing is used, the sample size aligns to 95/95 however this is equivalent to meeting a reliability of 95/99, so a 95/99 confidence/reliability can be claimed” (assuming high risk)?
A better description is “Since stress testing is used, demonstrating 95/95 under test conditions is equivalent to demonstrating 95/99 under normal usage conditions.”